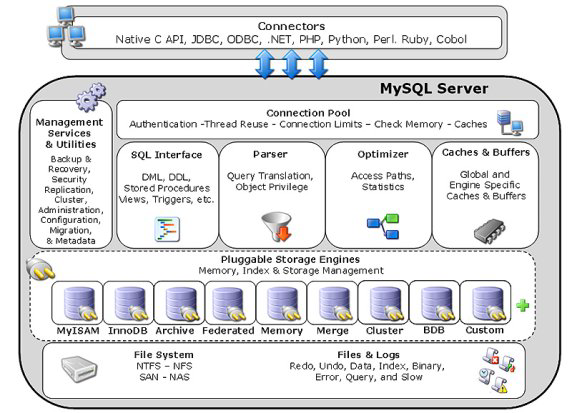
MySQL Architecture
Many companies use MySQL mainly because it's free, reliable, easy to setup and maintain. I have be using MySQL for many years but have never really gone into depth, mainly because once it has been installed it happily sits working for years with only slight modifications, the reason is that it is a simple database and not to bloated with many features that you don't need, the other feature is that MySQL can have a number of different engine types to suit the application.
MySQL is a open source database which means it's freely available with free redistribution, this means you have full access to the source code. MySQL began as Unireg that was developed by Michael "Monty" Widenius for a swedish company called TcX during the 1980's, the My part is Monty's daughters name. The initial release in 1995 had a SQL interface and a dual license model, a free and an embedded version. David Axmark, Monty and Allen Larrson founded MySQL AB in 1995, it was taken over by Sun Microsystems in 2008 and Sun itself was taken by Oracle in 2010.
MySQL is written in C and C++ and in 2001 MySQL began supporting transactions with the integration of the BDB and InnoDB engines (the default engine), this allowed for safer handling of concurrent write operations, which began the trend of adding features needed by the Enterprise environments.
MySQL supports the following platforms and has both 32-bit and 64-bit versions available
Although MySQL comes with no tools, there are a number of graphical tools available the main one being the MySQL workbench.
MySQL comes in a number of flavors, commercial customers have a number of different choices depending on your needs.
All the versions have the following features
Lastly before I start on the architecture there are a number of user community projects or resources that you may be interested in
MySQL is very different from other databases, in that it's storage engine is pluggable, what I mean by this is that the MySQL server core code is separate from the storage engine, which means that you can have a pluggable storage engine that fits your application. MySQL has over 20 storage engines, here is a list of the common ones
| Storage Engine | Transactional Support |
Locking Level |
Online Non-blocking Backup |
Server Version(s) available |
| InnoDB (default) | Yes |
Row |
Yes |
5.1, 5.5, 5.6 |
| MyISAM/Merge | No |
Table |
No |
5.1, 5.5, 5.6 |
| Memory | No |
Table |
No |
5.1, 5.5, 5.6 |
| Marta | Yes |
Row |
No |
5.1, 5.5, 5.6 |
| Falcon | Yes |
Row |
Yes |
5.6 |
| PBXT | Yes |
Row |
Yes |
5.1, 5.5, 5.6 |
| FEDERATED | No |
n/a |
n/a |
5.1, 5.5, 5.6 |
| NDB | Yes |
Row |
Yes |
5.1 and available in MySQL Cluster |
| Archive | No |
Row |
No |
5.1, 5.5, 5.6 |
| CSV | No |
Table |
No |
5.1, 5.5, 5.6 |
The different storage engines can vastly improve a database performance when using the correct one, below is a list of features that may make you decide to change from the default InnoDB storage engine
Although the idea is great sometimes you can get too bogged down on what engine to choose, hence why most mysql storage engines will be either be MyISAM or Innodb. I am only going to cover MyISAM, Innodb, MEMORY and CSV in depth, and leave you to the MySQL documentation regarding the others.
MyISAM was the default engine until recently, this engine has been used since MySQL version 3.2, it is a non-transactional engine and does not implement any additional locking mechanisms, this may cause problems when you have a large number of concurrent writes to a table. If your application has a lot of write activity the writes will end up blocking the reads which will cause performance problems, thus you should use either a InnoDB or Falcon engine.
MyISAM has three files associated with it, because the three files represent a table they can be simply copied to another server and used, however to avoid corruption you should take down mysql server before copying. The other server must have the same endian format as the source server, so you cannot copy from linux X86 server to a Sparc server for instance.
| .frm | the table format file |
| .MYD | the data file |
| .MYI | the index file |
MyISAM has the following features
You can set a number of parameters within the my.cnf configuration file that relate to the MyISAM engine
| key_buffer_size | Determines the size of the memory cache used for storing MyISAM indexes, the default is 8MB and the maximum is 4GB |
| concurrent_insert | Determines the behavior of concurrent inserts
|
| delay_key_write | Delays updating indexes for MyISAM tables until table are closed.
|
| max_write_lock_count | Determines how many writes to a table take precedence over reads, this helps with read starvation due to constant writes to a table, the default is 4294967295 I will cover this more in SQL Extensions section. |
| preload_buffer_size | Determines the size of the buffer used for index preloading of the key cache, the default is 32KB. |
There are three utility programs that can be used with MyISAM tables
| myisamchk | used to analyze, optimize and repair tables, to avoid data corruption you should shutdown mysql when performing any of the below actions. # check a table myisamchk /var/lib/mysql/<table_name>.MYI # Repair a table myisamchk -r /var/lib/mysql/<table_name>.MYI |
| myisampack | used to create compressed, read-only tables, to avoid data corruption you should shutdown mysql when performing any of the below actions. # compress a table |
| myisam_ftdump | used to display information about fulltext fields in tables # First you need the program to analyze, use show create table command |
I am just going to talk about the Merge Storage engine as it is related to the MyISAM one, it is actually a sort of wrapper around MyISAM tables with the same schemas. All underlying tables can be queried at once by querying the Merged table. This is one way on how to implement partitioning in MySQL, the merged tables use the same buffers and configurations as the underlying MyISAM tables. Two files are created .frm file contains the table format and the second file .MRG contains the names of the underlying MyISAM tables, as a side note you cannot use the replace statement with merged tables. The benefits of merged tables are better management of tables and better performance, using merged tables with smaller underlying tables not only speeds up these operations because of the smaller table size but it will allow you to rotate out the table from use by modifying the merge table definition to exclude it while maintenance is occurring.
InnoDB is now the default storage engine in MySQL, it has the following key features
With the Innodb storage engine you have control of the format and the location of the tablespace, a tablespace is a logical group of one or more data files in a database (yes the same as in Oracle), using parameters you can control the path the home directory and if you want to use separate files or a shared tablespace.
| innodb_data_file_path | Determine both the path to individual centralized data files (shared tablespace) and the size of the files |
| innodb_data_home_dir | The common part of the directory path for all InnoDB data files |
| innodb_file_per_table | If enable then any InnoDB tables will be using their own .idb file for both data and indexes rather than in the shared tablespace |
The full path to each shared tablespace is formed by adding innoDB_data_home_dir to each path specified in the innoDB_data_file_path, the file sizes can be specified in K, M or G. By default if innoDB_data_file_path is not specified a 10MB ibdata1 file is created in the data directory (datadir). You cannot just move the data files from one system to another like you can in the MyISAM engine.
There are a number of configuration parameters that you can use with the InnoDB storage engine
| innodb_buffer_pool_size | Determines the size of the buffer that the Innodb storage engine uses to cache both data and indexes |
| innodb_flush_log_at_trx_commit | Configures how often the log buffer is flushed to disk
|
| innodb_log_file_size | Determines the size (in bytes) of each of the Innodb log files, by default they are 5MB. Remember the bigger the file the slower recovery after a server crash. |
The larger the buffer the more data you can hold in memory which in turn increases performance, thus try to keep your most frequently used data in memory. Don't go too mad as to much memory could cause swapping by the operating system which in turn will degrade performance.
You can get detailed information regarding your InnoDB storage engine using the show command, there are a number of status sections which I will highlight now
| show command | show engine innodb status |
Innodb Status sections |
|
| semaphores | Reports threads waiting for semaphore and statistics on how many times threads have been forced to wait for an OS call, waiting on a spin wait, or a mutex or rw-lock semaphore. A large number of threads waiting indicates that there is a disk I/O problem or contention issues within the InnoDB. |
| foreign key errors | Displays information about foreign key problems |
| deadlocks | Displays information about the last deadlock that occurred |
| transactions | Reports lock waits, which may highlight lock contention within your application, it can also help detecting transaction deadlocks. |
| file I/O | Show activity about the threads used by the I/O |
| insert buffer and adaptive hash index | Displays information about insert buffer including size and amount of free space. |
| log | show information about the log files |
| buffer pool and memory | show buffer pool activity, including hit rates, etc |
| row operations | show activity of the main thread |
InnoDB uses shared tablespace for all tables and indexes that can consist of one or more files, hey are generally located in the datadir directory, the files contain metadata and are referred to as ibdata files. When the tablespace becomes fragmented the files are not shrunk, but the free space is still available to the database, you can view this free space by using the data_free field of the information_schema.tables system view and the data_free field of show table status.
You can have separate files instead by using the parameter innodb_file_per_table as mentioned above, however a small amount of metadata will be in the shared tablespace, to defrag the tablespace use the optimize table command which will be discussed in another section entitle SQL Extensions.
When working with ibdata files you can add additional files, these can be split over different disks, but with SAN replacing the old disk technology this seems a lesser requirement today, here are some examples on creating the ibdata files
| ibdata files | ## Create a 1GB ibdata file that will autoextend if needed ## create 1GB ibdata file and a second 1GB ibdata file that will autoextend |
MySQL will not stripe across disks, thus the first data file must be full before using the second data file, also some tables may be split across the two files when you start to use the second file, for example say that you have 1MB free in the first file and you create a 2MB table, 1MB will be in the first file and the second 1MB will be in the second file.
If you wish to change the size of the data files there is no easy way, the following steps must be taken
Due to the log files, InnoDB automatic crash recovery is possible, just like in other databases all changes are recorded in the log files and replayed back if the server were to crash. There are a number of parameters that can affect the log files
| innodb_log_files_in_group | the log files are written in a circular manner, they are initialized to there full size when MySQL starts |
| innodb_log_file_size | sets the logfile size in each group, the total size of all the logfiles must be less than 4GB, but this may be due to the O/S limitations so check with the latest MySQL release |
| innodb_fast_shutdown | this determines if logs files are purged during a shutdown which means it may take longer to completely shutdown MySQL
|
| innodb_flush_log_at_trx_commit | controls how often the log files are written to
|
| innodb_flush_method | changes how Innodb opens and flushes data log files, this is a trade off between performance and inconsistent data during a crash, I will discuss this further in tuning. |
| innodb_log_buffer_size | this is a write buffer for the log files, the larger the buffer the less often the log files are written to thus saving I/O. |
MEMORY storage engine creates a table in memory only, this allows for extremely fast data access, however the drawback is that data is not persisted across reboots, also if you replicate this table to a slave server, it will also truncate the slave table as well even though it did not restart. If rows are deleted from a memory table you must use either alter table or optimize table to defrag the table and reduce the amount of memory used.
The MEMORY storage has the following features
The MEMORY storage engine has a few parameters that you can tweak
| max_heap_table_size | the maximum size of MEMORY tables is limited by the system variables, default is 16MB |
| init_file | this can be used to specify a file to use to populate a MEMORY table when mysqld starts |
The last storage engine I am going to cover is the CSV storage engine (Comma Separated Value), it is simply a text file that can be manipulated with a simple text editor, this is ideal for data exchange or data importing.
CSV storage has the following features
Three files are created .frm which contains the table format, .CSM which contains metadata and lastly .CSV file which contains the data.
There are many other storage engines that may meet a particular need so I will leave you to the MySQL documentation on these.
The overall picture of MySQL is below
I want to explain how all this comes together inside MySQL, firstly you would create a database (or schema as it means the same thing), then inside each database you create tables that can be associated with a different type of storage engine, for example I could create four tables all using different storage engines all within the same database (schema), the picture below describes a single mysqld daemon running two databases/schemas each with fours tables, the tables can be associated with different storage engines.
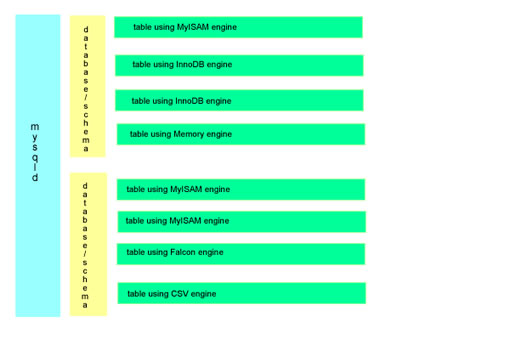
This is a totally different way of setting up a database to other databases like Oracle where there is only one engine.
Lastly the MySQL data dictionary is stored in the mysql database, a view only copy is stored in the information_schema database, it is a simple set of tables.
This is a short section on how to access MySQL, you have both commandline and GUI tools that allow you to access the mysqld daemon, you should really learn both. I prefer the commandline tool mysql it has a number of options
mysql Connect String |
|
| mysql | mysql -u pvalle -h mysqldb -ppassword <database> Note: when entering the password make sure there are no space between the password and the -p, if you don't specify a password then you will be prompted for one. |
mysql command options |
|
| -u or --user | You can specify a specific user |
| -p or --password | You can enter the users password |
| -h or --host | You can select a particular host which should have a running MySQL daemon |
| -S or --socket | You can select a particular socket, if on the same server as MySQL, then by default you would use the /tmp/mysqld.sock |
| -D or --database | You can select a particular database you want to connect too, you can specify the database without using these options as in the example above |
| -V or --version | obtain the version number |
| -v or --verbose | display more verbose output, good for tracking down problems when the connect string is not working |
| --delimiter | change the default delimiter which is a semi-colon (;) |
| --protocol | You can select a different protocol to use
|
You also have the option to feed in either a sql file or sql commands from the commandline
| mysql and sql commands | mysql -u pvalle -h mysqldb -ppassword <database> -e "select * from mysql" mysql -u pvalle -h mysqldb -ppassword <database> < sql_commands.sql |
Once you have connected to MySQL, there are a number of useful commands
| List all commands | help \h ? |
| List databases | show databases; |
| Select a particular database | \u mysql use mydatabase |
| Change the delimiter | \d @ delimiter @ |
| Change the output to vertical | # Just put a \G at the end of the select statement instead of the normal delimiter select * from tables\G |
| Run a shell command | \! uptime |
| list connected database and user | select user(), database(); |
Another useful command is mysqladmin, which allows you to perform adminisitive tasks
| Command | Usage | Description |
| create | mysqladmin create test2 | create a database called test2 |
| debug | mysqladmin debug | send additional detailed logging to the error log |
| drop | mysqladmin drop test2 | drop the database called test2 |
| extended-status | mysqladmin extended-status | displays mysqld system variables and their current values |
| flush-hosts | mysqladmin flush-hosts | clears internal information about hosts including the DNS cache and hostnames blocked due to too many connection errors |
| flush-logs | mysqladmin flush-logs | flushes server logs by closing current logs and reopening new log files. |
| flush-privileges | mysqladmin flush-privileges | reloads the grant tables, thus refreshing users privileges |
| flush-status | mysqladmin flush-status | resets most server status variables |
| flush-tables | mysqladmin flush-tables | closes currently open table file handles, it waits for the current thread connections to finish before releasing file handles used by those connections |
| flush-threads | mysqladmin flush-threads | resets the thread cache |
| kill | mysqladmin kill 50 | kill specified client threads |
| password | mysqladmin password <password> | change the connection password for the user account specified |
| old-password | mysqladmin old-password <password> | change the connection password for the user account specified, however stores the password in the old less secure way using 16 characters instead of 41 characters |
| ping | mysqladmin ping | determines if the server is online and available |
| processlist | mysqladmin processlist | displays all active server threads |
| reload | mysqladmin reload | see flush-privileges |
| refresh | mysqladmin refresh | similar to flush-hosts and flush-logs |
| shutdown | mysqladmin shutdown | stop the mysqld daemon cleanly |
| start-slave | mysqladmin start-slave | starts replication |
| status | mysqladmin status | Displays a number of global status variables |
| stop-slave | mysqladmin stop-slave | stop replication |
| variables | mysqladmin variables | displays the global status variables and values |
| version | mysqladmin version | displays the version of MySQL |
With some of the mysqladmin options you can use two additional options --sleep and --count, if you have ever used vmstat in the unix world then they act in the same way, for example you could use the following command to take readings every 5 seconds for 5 times, you can also use --debug-info to get additional information on the status for example
| sleep and count | mysqladmin status --sleep 5 --count 5 |
| --debug-info | mysqladmin status --debug-info |
Lastly there are a number of GUI tools that do the same thing as above, I prefer the commandline but some people prefer a GUI, here are some that you can download and try